Reply 60 of 74, by dexvx
More partial responses.
wrote:Cherry-picking is where you only pick the results that support your argument. In some cases that can be people only picking the 'outliers' where their brand of choice is faster, discarding the results that bring the average down.
In other cases, people may discard the 'outliers' where their brand of choice is slower.
???
I literally picked the upcoming AAA title that is going to be released (it was released on Oct 3, a few days prior to my post). It was purely coincidental that it is super optimized for Radeon at the moment. I would've done the same for Destiny 2 and SW: BF II, regardless of outcome.
wrote:In the case of DX12/Vulkan, the sample space is currently too small to even have a good idea of what the expected results are, vs what the outliers would be.
True (I discount 'ported' titles unless it was a total revamp), but that doesn't mean you can dismiss results as they are coming in.
wrote:Game devs don't necessarily understand hardware these days. Heck, many of then don't even know assembly language anymore. They're probably doing the same as you do: repeat stuff they read on the internet, because confirmation bias.
Really, you'll have to come up with something better.
Confirmation bias that is confirmed by real world application results. Sure.
wrote:As far as I recall, Maxwell can very well change the SMs on the fly (as pointed out, they have been able to do that since Kepler with HyperQ), the only limitation being that it cannot do it while a draw call is executing, because draw calls are not pre-emptive. So it can change the SMs between any two draw calls.
In which case you are misunderstanding the hardware and misrepresenting the facts.
Let me spell out the problem for you in Maxwell. I can change SM allocations on the fly, yes. But how the fvk am I supposed to know ahead of time what I'm going to change it to? Am I supposed to dynamically detect when an end user (e.g. gamer) happens wander to somewhere that requires ALU heavy work (thus needing more compute)? You can't be serious when you say 'let's change it on the fly' as a solution. That's akin to scheduling CPU workload manually (without an OS scheduler).
wrote:Why do I have to need to cite anything? How about common sense? They released a benchmark which had worse performance on Maxwell […]
Why do I have to need to cite anything? How about common sense?
They released a benchmark which had worse performance on Maxwell when async is enabled.
If you didn't want to hurt performance on NV, you would either not enable the async path at all, or you would make an alternative path that doesn't hurt performance.
In fact, why would they even release a benchmark at all, of a game that was still far from finished at the time?
Not to mention that AoTS was an AMD-sponsored game, so the writing is on the wall, isn't it?
Because your wording was malicious towards AoTS. If you think that's an outlier (which I think it is, btw), than that would be acceptable. But no, because AoTS is developed in a way that's unfriendly to Maxwell (at the time), you go on and denigrate them.
I could literally say the same thing about Project Cars (where it performs like sh1t on Radeon).
wrote:Putting the cart before the horse, are we?
The point of writing a game should be to make it run as fast as possible, and make it look as good as possible. What you're saying just proves my point: they ran a task that was structured in a way that it ran very poorly on Maxwell.
Actually, the point of writing a game is to get as many sales as possible. There are plenty of titles that run like sh1t on both Nvidia and AMD hardware (Dishonored). In a perfect world, game companies release bug free games running optimally on all hardware paths while looking superb, but the reality is that 'good enough' performance is the target. Squashing user bugs is far more important than eeking out that last 20% more performance. Unless... some hardware company who wanted to show off certain aspects of their hardware wanted to pay for that development. And since Nvidia has way more free cash than AMD, guess which way game companies usually go?
wrote:Why would you even allow such a code path to run on the hardware? QA should have figured out that this didn't work on that hardware, so you disable it. After all, async compute doesn't change anything about how the game looks. It's merely a basic tool that may or may not allow you to get small gains on certain hardware if you can use it correctly.
It should be disabled by default, unless you made specific optimizations and have verified that they indeed improve performance during QA. This is also what the DX12 best practices docs say.
Instead, not only did they enable it by default, they even went as far as shout out in the media that NV's hardware was broken and whatnot. Which is what got us to where we are today, with people like you arguing about how only AMD has "true async". It's a dirty game that AMD has been playing, and you fell for it.
So you're upset that a beta build of AoTS had async compute enabled by default, and a bunch of reviewers posted stuff about it and sent the fanbois crazy? Last I heard, the released version of AoTS had async compute not enabled by default if it detected a Maxwell based card.
And please cite where the AoTS devs directly say Maxwell hardware was broken. And yes, I stand by my wording saying Maxwell has software async compute due issues I've outlined above.
wrote:See, async compute is mainly an AMD marketing tool. It is basically the only DX12-thing that they can sorta do. Not to mention that they get it 'for free' on the PC platform since game devs also use it on consoles.
As a result, AMD's DX12 strategy has been to focus 100% on async compute (and completely ignore other new features of the API, many of which they didn't even implement). The only software out there that uses async compute and ISN'T AMD-sponsored/biased is FutureMark's Time Spy.
You are quite correct about AMD using async compute as a marketing tool throughout the Hawaii/Fiji era. Nvidia was totally silent about the whole thing until Pascal. Then magically with Pascal, Nvidia was talking about async compute and its potential publicly (GDC). How curious and convenient that Nvidia was embracing async compute just when they had capable hardware!
wrote:Pretty much everything else is "Look, AMD is faster, NV is fake!", which is nonsense of course. It's about as nonsensical as saying that AMD's CPUs must be 'pseudo-hardware' because they can't run x86 software as quickly as Intel can.
Different architectures just have different solutions to the same problem, which comes with different performance characteristics and optimization strategies.
Oh now you're venturing into my space. Actually AMD CPU's cant run x86 (+full extensions) as well. I mean FFS, there was a time where Ryzen can't compile in certain situations*. And it's confusing to say 'run x86 as fast as', as compute speed varies on workload (int vs fp in a general sense). For fp, Zen has much lower fp throughput (16 ops/clock with 2x 256bit FMA vs 8 ops/clock with 2x 128bt FMA) for whatever reason. I would venture that they envision their servers to have Zen as int and Vega as fp.
x86 also includes many extensions. AMD usually falls behind on implementing said extensions. E.g. Ryzen AVX-256 implementation is 4x 128bit units that can be paired for a 256bit op. However, only one pair can do add and one to do mul. Compared to Skylake AVX-256 where it is 2x 256bit units that can do add or mul per unit. They're also missing AVX-512 extensions.
And their CCX structure is a mess at higher core counts (cross CCX is a massive penalty due to limited fabric). Surprise! It depends on how you schedule your workload.
* https://www.phoronix.com/scan.php?page=news_i … Compiler-Issues
So feel free to take your leave from CPU world 😀
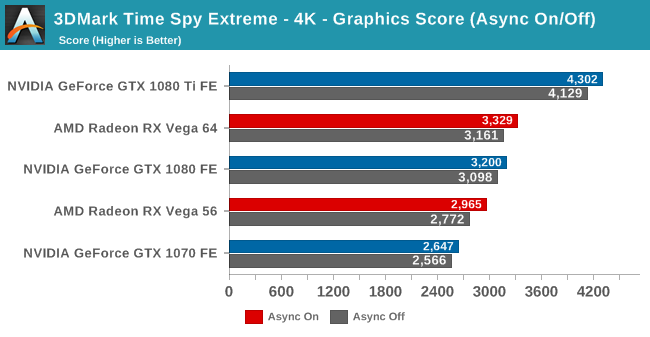
wrote:Time Spy is the only 'fair' async compute test we have so far, and we can see that it indeed works on NV hardware. It doesn't get as much as a boost as it does on AMD hardware, but does that make NV's bad or fake? No. Their architecture is just different. As I already said before, NV's pipeline is far more efficient than AMD's, so there is less to gain with async compute in the first place. Even if NV would copy AMD's async compute implementation 1:1 and glue it onto Pascal, you wouldn't see the same gains as you get on AMD hardware.
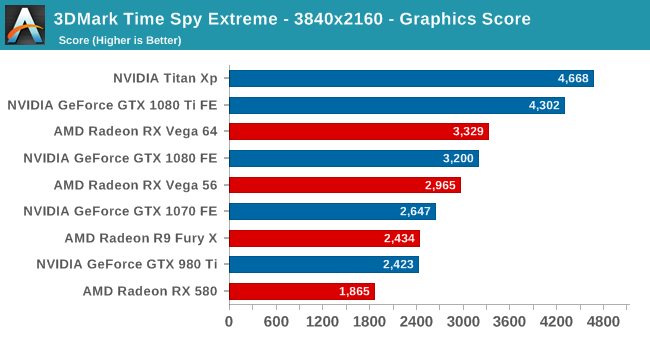
Speaking of which.