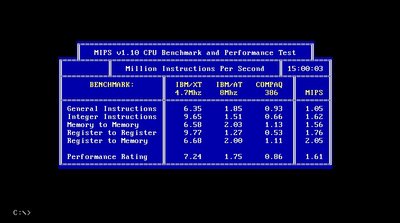
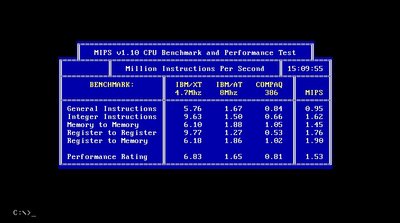
I am not sure if we talked about this before, but I assume that in a given cycle the processor can read more than 1 byte from the BIU prefetched data. In fact it can read 16bits if prior to 386 and 32bits otherwise. So I am thinking it is like this:
8088/8086 - can read 16bits (2 bytes) per cycle from prefetch queued (data that is already prefetched)
80286 - 16bits (2 bytes)
80386SX and DX - 32bit (4 bytes).
Why is this important? Well if I have an instruction that say requires an immediate, if that immediate is 16 bits then we have the following number of cycles to process (*)
8088 - 8 cycles to fetch 16bits and 1 cycle to read it from BIU
8086 - 4 cycles to fetch 16bits and 1 cycle to read it from BIU
80286 - 2 cycles to fetch 16bits and 1 cycle to read it from BIU
If I have a 32bit immediate in the instruction a 80386 (DX or SX) will take that long
80386SX - 2 cycles to fetch 32bits and 1 cycle to read it from BIU
80386DX - 1 cycles to fetch 32bits and 1 cycle to read it from BIU
Is my assumption correct?
(*) Under ideal circumstances, excluding waitstats and other bus operations that might stop the bus like DMA, etc.
I think that's mostly correct for plain MMU/IO accesses, but the PIQ is always read in 1 byte/cycle, while it might fetch words or dwords from memory into the PIQ, but I'm not 100% sure(especially since there exist cases like fetching offset 0xFFFF in 16-bit mode)?
Edit: Also, a 80386DX+ still fetches data in 2 cycle minimal, for any byte/aligned (d)word?
1When used in a configuration with a 32-bit bus, actual transfers of data between processor and memory take place in units of doublewords beginning at addresses evenly divisible by four;
So, essentially for small instructions taking a bit of time(4 cycles) will always have the prefetch non-empty due to the ridiculously fast memory access times(4 prefetch bytes in 1 cycle, then up to 4 cycles to read into the EU)? Thus 5 cycles for 4 bytes or simply 1.25 cycle per instruction byte or lower for small instructions?
Also, that only explains the fetches themselves, nothing is said about it being 1-cycle?
Also, that only explains the fetches themselves, nothing is said about it being 1-cycle?
My comment of 1 cycle for 386DX is about the prefetch itself. Why would it be not 1 cycle? Where is another cycle wasted on?
vladstamate wrote:
80386DX - 1 cycles to fetch 32bits and 1 cycle to read it from BIU
I also doubt the 386 reads 1 byte at a time from the prefetched data buffer. That would be terribly unperformant. My guess is it either reads as much as it needs in 1 cycle (up to 4 bytes) or (much less likely) up to 2 bytes.
The question is what does 386SX do, and also what doe 286 do when they read from prefetched data buffer. Again, my guess is 386SX can read 4 bytes and 286 can read 2 bytes at a time (if necessary). Alignment does not matter anymore as we are reading from prefetch buffer, not actual memory.
So, essentially for small instructions taking a bit of time(4 cycles) will always have the prefetch non-empty due to the ridiculously fast memory access times(4 prefetch bytes in 1 cycle, then up to 4 cycles to read into the EU)? Thus 5 cycles for 4 bytes or simply 1.25 cycle per instruction byte or lower for small instructions?
I think that is true. In reality however you might have other things contending with the bus and also 386 has WS 1 (or more) memory IIRC.
The 8088 and 8086 cannot remove more than one byte from the prefetch queue in any given cycle. We know this because the 8087 needs to track the state of the prefetch queue and the interface it uses to do so doesn't have any way to signal more than one byte removed in any given cycle.
Does that one-byte at a time way of fetching instructions from the PIQ happen with later (286+) processors as well? So even during 16-bit and 32-bit immediate operands of an instruction(e.g. ADD EAX,00000001h with opcode 05h)? And the data is fetched into the PIQ from RAM/MMIO in dword quantities when possible(dword aligned address) or word quantities(word alignment, then followed by dword quantities) else byte quantities(byte alignment, after that word or dword quantities depending on alignment)? Also, there's the whole case of protection involved as well, so how does that all combine? Say you are at a dword aligned address, but the fourth byte is outside segment limits or outside paging limits, what happens? Three bytes fetched, fourth cleared? Entire fetch aborted as an error? Word fetch followed by byte fetch, then fetching is stopped?
Does that one-byte at a time way of fetching instructions from the PIQ happen with later (286+) processors as well?
The 286 doesn't have the queue status interface that 8088/8086/80188/80186 have, so I have no way to know the size of the remove-from-prefetch-queue bus. I'd expect they'd have made it 16 bits by the time of the 80286 and 32 bits by the time of the 80386, but that's just a guess.
Does that one-byte at a time way of fetching instructions from the PIQ happen with later (286+) processors as well?
The 286 doesn't have the queue status interface that 8088/8086/80188/80186 have, so I have no way to know the size of the remove-from-prefetch-queue bus. I'd expect they'd have made it 16 bits by the time of the 80286 and 32 bits by the time of the 80386, but that's just a guess.
Yes, no way 386 did get 1 byte at a time. Yes, there are all the complications about protections faults and unaligned reads and so on. But in the ideal circumstances when none of that happens if the EU needs a 32bit quantity for a 32bit ADD EAX, imm lets say, then I suspect it will just swoop that in 1 go if all of it is in the queue.
Ohh, interesting! I did not account for that. Do you happen to have a link or a document where I can find more about this?
This brings even more questions, like is the IU fetching the immediate values (of any) as part of its decoding?
Not much more info, just wikipedia and intel manuals.
Apparently EA calculation is performed in a dedicated unit as well, so it's not done on ALU any more.
That's also obvious from block diagram; there is a block called addressing unit (AU) as well.
Apparently EA calculation is performed in a dedicated unit as well, so it's not done on ALU any more.
That's also obvious from block diagram; there is a block called addressing unit (AU) as well.
In the light of what you said, this makes sense: that is probably to help with the pipelining. I assume so that IU can do EA as part of decoding while the EU is executing instructions (which might require the ALU).
I've just modified the instruction fetching to be allowing single-cycle word/dword fetches from the PIQ, as well as updated my BIU emulation to be able to fetch 16-bit and 32-bit quantities from memory(as long as it's aligned, although I'm not 100% sure the check for odd 16/32-bit subunits is going 100% OK):
Fetching process itself:
1byte PIQ_block = 0; //Blocking any PIQ access now? 2OPTINLINE void CPU_fillPIQ() //Fill the PIQ until it's full! 3{ 4 uint_32 realaddress; 5 if ((PIQ_block==1) || (PIQ_block==9)) { PIQ_block = 0; return; /* Blocked access: only fetch one byte/word instead of a full word/dword! */ } 6 if (unlikely(BIU[activeCPU].PIQ==0)) return; //Not gotten a PIQ? Abort! 7 realaddress = BIU[activeCPU].PIQ_Address; //Next address to fetch! 8 checkMMUaccess_linearaddr = (CPU[activeCPU].SEG_base[CPU_SEGMENT_CS]+realaddress); //Default 8086-compatible address to use, otherwise, it's overwritten by checkMMUaccess with the proper linear address! 9 if (unlikely(checkMMUaccess(CPU_SEGMENT_CS,CPU[activeCPU].registers->CS,realaddress,0x10|3,getCPL(),0,0))) return; //Abort on fault! 10 if (unlikely(is_paging())) //Are we paging? 11 { 12 checkMMUaccess_linearaddr = mappage(checkMMUaccess_linearaddr,0,getCPL()); //Map it using the paging mechanism! 13 } 14 writefifobuffer(BIU[activeCPU].PIQ, BIU_directrb(checkMMUaccess_linearaddr,0)); //Add the next byte from memory into the buffer! 15 if (unlikely(checkMMUaccess_linearaddr&1)) //Read an odd address? 16 { 17 PIQ_block &= 5; //Start blocking when it's 3(byte fetch instead of word fetch), also include dword odd addresses. Otherwise, continue as normally! 18 } 19 ++BIU[activeCPU].PIQ_Address; //Increase the address to the next location! 20 //Next data! Take 4 cycles on 8088, 2 on 8086 when loading words/4 on 8086 when loading a single byte. 21}
Main calling, which fetches bytes/words/dwords in one go(in byte subchunks, checking each one of them until an error occurs or misalignment(caused by PIQ_block cleared bits):
1 PIQ_RequiredSize = 1; //Minimum of 2 bytes required for a fetch to happen! 2 PIQ_CurrentBlockSize = 3; //We're blocking after 1 byte access when at an odd address! 3 if (EMULATED_CPU>=CPU_80386) //386+? 4 { 5 PIQ_RequiredSize |= 2; //Minimum of 4 bytes required for a fetch to happen! 6 PIQ_CurrentBlockSize |= 4; //Apply 32-bit quantities as well, when allowed! 7 } 8 if (BIU_processRequests(memory_waitstates)) //Processing a request? 9 { 10 BIU[activeCPU].requestready = 0; //We're starting a request! 11 ++BIU[activeCPU].prefetchclock; //Tick! 12 } 13 else if (fifobuffer_freesize(BIU[activeCPU].PIQ)>PIQ_RequiredSize) //Prefetch cycle when not requests are handled(2 free spaces only)? Else, NOP cycle! 14 { 15 CPU[activeCPU].BUSactive = 1; //Start memory cycles! 16 PIQ_block = PIQ_CurrentBlockSize; //We're blocking after 1 byte access when at an odd address at an odd word/dword address! 17 CPU_fillPIQ(); CPU_fillPIQ(); //Add a word to the prefetch! 18 if (PIQ_RequiredSize&2) //DWord access, when allowed? 19 { 20 CPU_fillPIQ(); CPU_fillPIQ(); //Add another word to the prefetch! 21 } 22 ++CPU[activeCPU].cycles_Prefetch_BIU; //Cycles spent on prefetching on BIU idle time! 23 BIU[activeCPU].waitstateRAMremaining += memory_waitstates; //Apply the waitstates for the fetch! 24 BIU[activeCPU].requestready = 0; //We're starting a request! 25 ++BIU[activeCPU].prefetchclock; //Tick! 26 } 27 else //Nothing to do? 28 { 29 BIU[activeCPU].stallingBUS = 2; //Stalling! 30 }
Edit: Fixed up the data transfer size on 32-bit quantities a bit:
1 if ((PIQ_RequiredSize&2) && ((EMULATED_CPU>=CPU_80386) && (CPU_databussize==0))) //DWord access on a 32-bit BUS, when allowed?