First post, by mpe
Rank
Oldbie
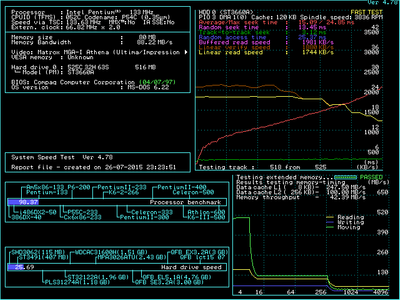
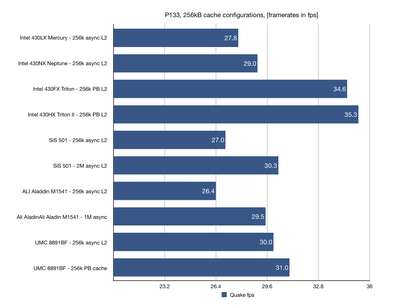
I am working on a project, where I am comparing performance of some selected early chipsets from Socket 4 and Socket 5 era. So far I've tested the the following:
- Intel 430LX (Mercury)
- Intel 430NX (Neptune)
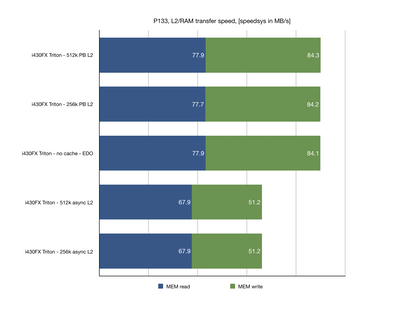
- Intel 430FX (Triton)
- Intel 430HX (Triton II)
- ALI M1451 Aladdin
- UMC UM8890
- SiS 501

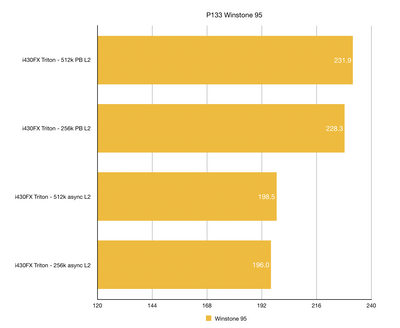
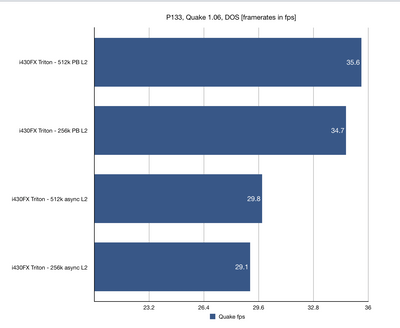
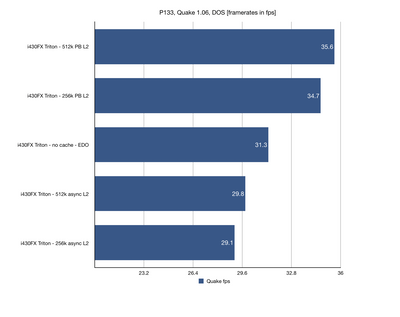
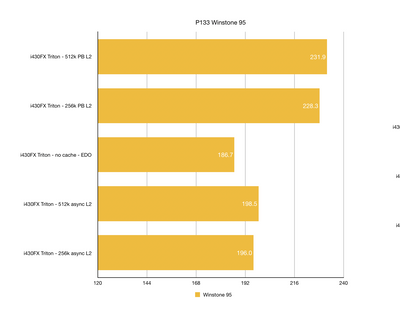
I got the first results in and I thought it might be interesting to share them. Unsurprisingly, Intel Triton runs in circles around the competition. However, there are some nice 3rd party choices too. I was surprised by strong result of UMC8891BF chipset which reportedly has 486 architecture (which I found not to be true).
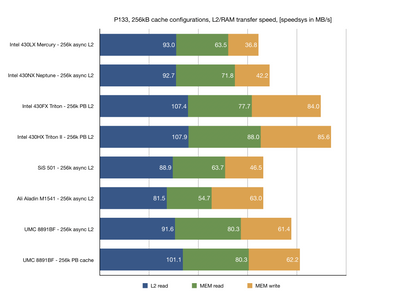
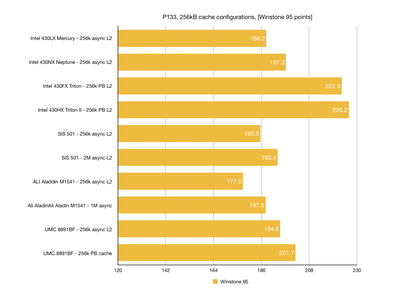
This is still WIP and I'd like to cover more chipsets from this era. Specifically different revisions of UMC, Intel chipsets with different cache configurations, SiS 5501, Opti Python/Cobra/Viper and more.
More details are in this blogpost.