These post should help you diagnose poor memory performance on 486 boards. For general use, a configuration is preferable in which the complete memory is cacheable in L2 cache, and the L2 cache operates in write-back mode with a "dirty tag bit". On modern 486 chipsets (like the UMC 8881 or the SiS 496), the dirty tag bit may reside in the tag RAM, whereas older chipsets (like the Intel Saturn or the SiS 411 EISA chipset) need a dedicated chip for the dirty bit. For general purpose, the three different cache modes are, in order of preferability:
- Write-back using a dirty bit
- Write-through
- Write-back assuming always dirty
If you use a chipset that supports borrowing a tag bit as dirty bit, you should be aware that borrowing a tag bit means halving the cacheable area. Most 486 boards use an 8 bit wide tag and direct-mapped L2 cache. In these circumstances, the cacheable area is 256 times the cache size, i.e. 64MB for 256KB L2 cache, 128MB for 512KB cache and 256MB for 1MB L2 cache. If you reassign one of the 8 tag bits to be the dirty bit, 256KB of cache (the most common configuration) is only good for 32MB of RAM. Getting all RAM cached in the L2 cache is generally preferred to enabling write-back cache. If you have the standard configuration of 256KB cache and 8 tag bits (i.e. 9 chips with 28 pins each), use the L2 cache in write-through mode if you install 64MB RAM, unless you know exactly what you are doing, like creating a RAM disk in uncached RAM.
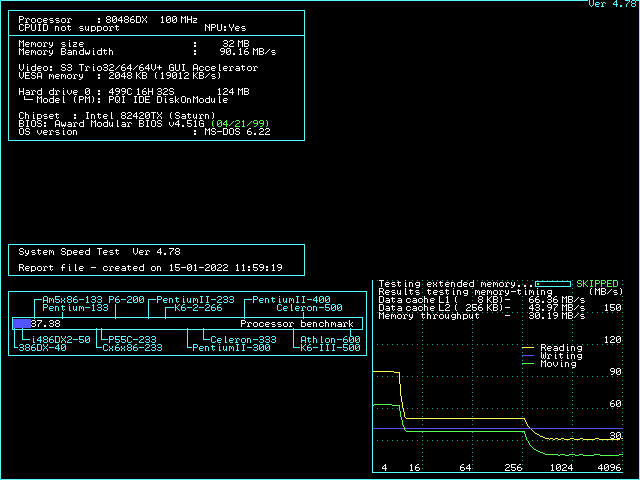
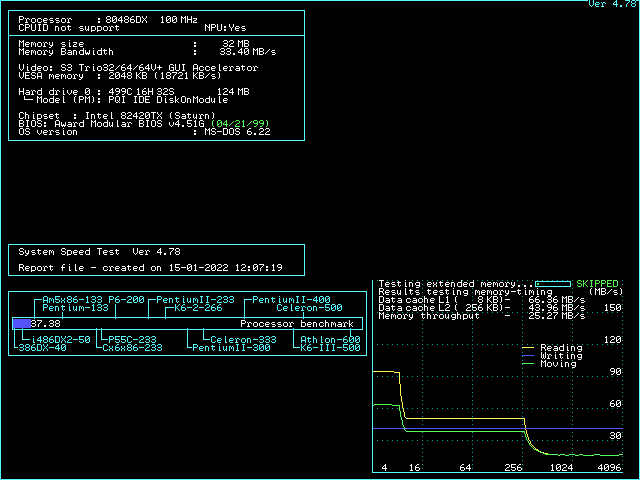
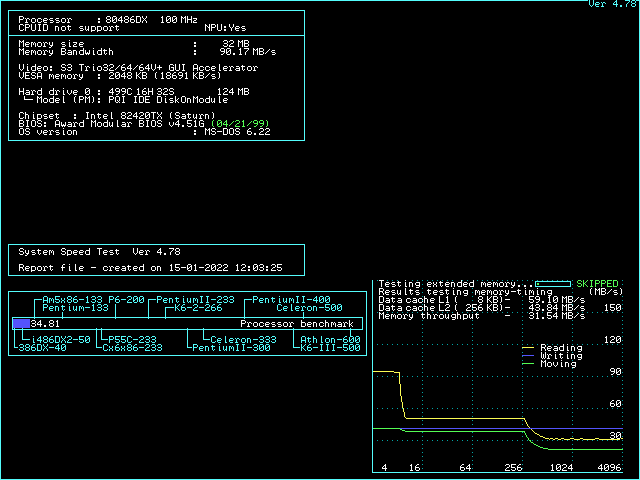
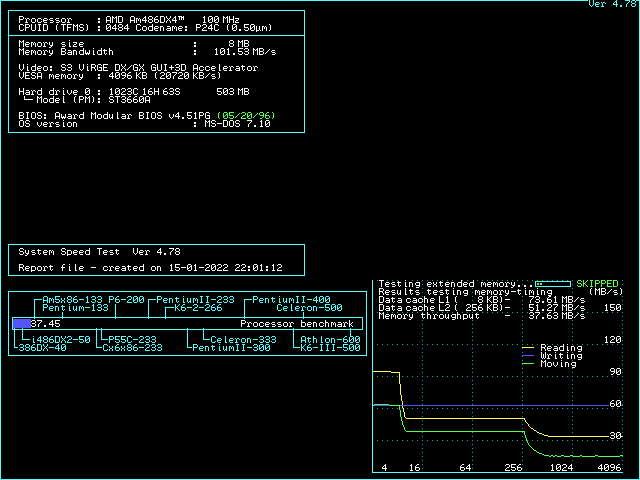
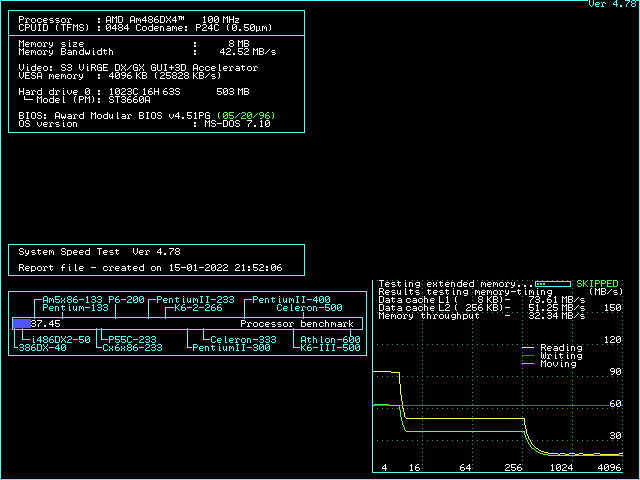
If you use ctcm to diagnose the cache configurations, don't blindly trust the cache strategy detected by ctcm. Instead, detect the strategy yourself. Take a look at the first 5 throughput lines. If all of them are different, your board operates in L1WB mode with proper dirty support. If the 3rd to 5th are all equal, your L2 cache is running in write-through mode. If the 3rd and 4th are identical, but the 5th is lower, you are operating in write-back mode without dirty support. For better performance, you should find a way to either switch to write-through mode or get dirty support.
The technical background: The idea of write-back is that if the CPU writes to some memory cell, and that cell is cached in the L2 cache, the write doesn't go through to memory, but only the L2 cache is updated. This is faster than hitting memory every time. If the data in the L2 cache is updated and the memory in RAM is stale, the part of the L2 cache that has been updated is called "altered" or "dirty" (these terms are synonyms). If some other data is going to be cached where the dirty data is, the dirty data needs to be committed to memory. I don't know about any 486 chipset that writes back dirty cache lines "in the background" when the memory is idle, but write-back from cache to memory happens at the last possible time: Directly before the data in the cache gets replaced. The consequence is: When the CPU reads a memory cell that is not in the L2 cache, and the part of the L2 cache where that data is going to be stored, the CPU is stalled until the dirty part of the L2 cache (16 bytes) got written to memory and the requested data is subsequently copied into the L2 cache and forwarded to the CPU. A memory access that misses the L2 cache thus is significantly slower in a write-back system where the L2 cache is dirty than in a write-through system (in which the L2 is always clean). You probably can already estimate the performance disaster that will arise if a write-back L2 system doesn't store whether a cache part is dirty or not: It always has to assume the L2 cache is dirty, and also issues write-back cycles when the L2 cache is actually clean. And as I just discussed, L2 write-back cycles hurt because they stall the CPU as it waits for the data it tries to read. A properly operating L2 write-back system is supposed to make up for the performance loss caused by the write-back cycles by being faster on write hits into L2 cache.
Knowing the background, we can take a look at the speedsys diagrams and understand why these diagrams might be misleading if you don't exactly understand what situation is measured. Most prominently, on all 486 sytems, the "write" performance in speedsys is a straight horizontal line, even if write-back cache is enabled. It seems as if the write-back cache isn't helping writing at all. This is an artifact caused by the way speedsys performs the measurement: Speedsys allocates a 4MB area, and aligns all tests to the beginning. That means the 4MB read test reads the complete area from start to end. At the end of the read test, the last 256KB of the test area are cached in the L2 cache (assuming 256KB cache). The write test the writes to the beginning of the 4MB test area which is not in the cache, so all the writes are misses. That explains why you don't see any effect of the cache in the speedsys write benchmark. This is a rare case in real-world applications, though. Real-world applications often write into memory locations that were read just before (like incrementing a variable), which would cause a write hit. Speedsys is thus unable to detect the performance improvement a write-back L2 cache can have to write cycles.
The speedsys "moving" test on the other hand seems to read the memory and copy it back to the same address. This means that all the write cycles are hits now, and as long as the test area is fully backed by the L2 cache, no write cycles to memory happen at all in the write-back scenario. This is the best case for a write-back cache, and as no write back cycles happen, the speedsys diagram looks the same with and without dirty tag support as long as the L2 cache size is not exceeded. On the other hand, as soon as the L2 cache size is exceeded, the presence or absence of the dirty bit (per cache line) is clearly visible: If every line is assumed to be dirty, all the stuff read from main memory into the L2 cache will need to be written back to memory again, so the amount of data transferred between memory and L2 cache is identical in the "reading" and the "moving" cache. If the dirty tag bit is present, though, the chipset will omit the write back cycles in the "reading" bench and only perform them in the "moving" bench. This explains why the slow part (where L2 size is exceeded) has the read performance drop to the move performance if the dirty bit is missing.
There are some further interesting insights you can take from the diagrams: The moving bench (for block size > L2 size) performs better in L2 WT mode than in L2 WB mode. This is because in L2 WT mode, the writes to main memory happen as soon as possible, so the memory bus is never idle, whereas in L2 WB mode, writeback happens when the CPU starts accessing a new cache line (stalling the CPU), then the new line is fetched to L2 cache and L1 cache. As soon as the cache line is completely filled, the CPU starts writing the new contents for the cache line to L2 cache (which is not yet written to memory, because that's the point of L2WB). The memory bus is thus idle during the time the CPU needs to write the updated data back to L2 cache. Only when the CPU starts to require the next line, a new write-back cycle from L2 cache to memory is initiated. As the bottleneck of the "moving" bench for big blocks is the memory bus, every cycle the memory bus is idle decreases the score in this benchmark.
Finally, if your board is slow enough on memory writes that the memory writes are a bottleneck for the "moving" bench (which is the case for the Saturn II board, but not for the UM8881 board), you can see a significant improvement in the "moving" score for small blocks if L2WB is enabled (with or without dirty tag). In the "moving" bench for small blocks, all writes are hits, and all memory writes are eliminated.