maxtherabbit wrote on 2023-09-27, 20:34:
I guess we kinda already knew this, but whatever the problem is with this 73GB drive on this system is specific to the CHS type int 13 calls. If I partition/format it with a single 100% FAT32 partition it actually works fine. The format will crash at the end as shown in my screenshot before, but after a reboot the drive is actually accessible in DOS.
I don't think it matters whether you do CHS-style or LBA-style calls. In both cases, the read and write calls don't know and don't care about how big the drive actually is. The LBA-style call just forwards the LBA to the SCSI drive, and the CHS-style call uses the number of "heads" and "sectors per track" to calculate an LBA from the CHS value. After that, they are processed in the same way (at least after I fixed the ID0 bug). You should be able to test my theory the LBA vs CHS doesn't matter by trying to re-create the FAT16 partition that causes the issue, and switching between type 6 (which makes IO.SYS use CHS calls) and 0E (which makes IO.SYS use LBA calls). I don't expect any difference.
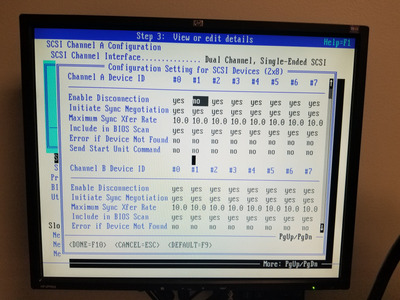
The strongest indication that we are not dealing with an geometry calculation issue is the drive LED that stays on. Both the CHS and the LBA code calls the same "SCSI execution engine" function. This function is supposed to turn on the LED, run the SCSI command, and then turn the LED back off. If the LED keeps stuck on, this execution function "forgot" to turn it off, probably because some timeout handling in it is buggy. As SCSI command execution (at least on the level supported by the basic input/output system) is very straightforward (you select the device, the device asks for a control message that selects the LUN, the device asks for the command to execute, which will be a 10-byte sized data block containing the read or write command, the device requests to transfer data, then the device requests to send a status byte, which will indicate "OK", and finally the device requests to send a message which will be "command complete". It's difficult to mess this up, especially if you have hardware that supports the software with recognizing what kind of action is currently requested by the device. The is only one thing that can complicate the handling of SCSI command execution - and that is a device sending special control messages during the transfer. These device may interrupt the normal SCSI command execution process any time to send a control message. The most prominent use of the "interrupt execution and send a message" system is the "disconnect" feature. When the device detects that it will take some time until the next byte can be transferred, it will switch from the "data" phase to the "message in" phase, and send a "DISCONNECT" message. In that case, the bus will be freed after the host adapter receives the message, and the device will "re-select" the host adapter later to continue the execution of the command. The disconnect/reconnect process during transfer can be combined with "SAVE POINTERS"/"RESTORE POINTERS" which controls what data range will be transferred after re-connection. This adds a lot of complexity to the process, which makes it much easier to break. So my intuition is that the Atlas firmware sends SCSI messages in a way or timing that is incompatible with the more recent BIOS versions. My suggestion to try with "disconnect" disabled (via the ECU) still stands. If disabling disconnect helps, I may take a look at what changed regarding SCSI command execution, and whether I can identify some sequence that would cause the execution engine to deadlock.