Socket3 wrote on 2024-03-07, 21:49:Well, I gave her a good wash and inspected her under the microscope... new paste, fresh pads... but still no dice...
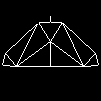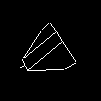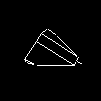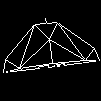
Card will POST, driver installs, no artefacting, everything runs fine in 2d.... Managed to run the first half of the 3dmark 01 "car chase" test, and then it locked up. No black screen this time, it just locked up. It's perfectly happy to sit in desktop, left it idle for 30 mins, brosed the web for 30-40 mins after that, but again, as soon as I run any 3d app it freezes.
Sounds exactly like the countless number of faulty GPU's I've ran across over the years. But that's what happens with the stock coolers on these older nVidia cards. They typically run in the upper 70's under 3D load, and that's really too much for them. The latter-made GF6 series are even more sensitive to this, though nowhere near as bad as the GF7 and 8 series, which are right-smack in the middle of the bumpgate issue.
Re-ball is not going to help it any more than a reflow - it's the solder between the GPU die and the substrate (PCB of the chip) that's starting to fail.
If you do reflow it and you do get it to work, the only way to keep it working fine for any reasonable amount of time would be to ditch the stock cooler and go for something that can handle at least 100 Watts of TDP comfortably and keep the 3D / max load running temperatures under 60C. It's still no 100% guarantee, but IME it vastly increases the chance that the reflown GPU will last afterwards.
And if you don't want to mess with reflowing/reballing, just chuck it back on eBay or some other place like that as TESTED & NOT WORKING with a $0.99 starting bid. Believe it or not, people will still buy these. Just that you won't get as much for it as you would for a working card. Probably going to sell for $10-15, depending on who's looking for such cards at the moment (I used to be one of those people, but have moved across the pond, so stuff from eBay USA is no longer a good deal to me due to shipping charges.)
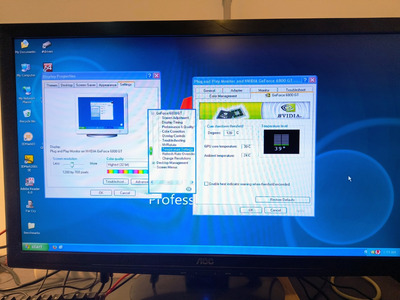
Before attempting a reflow/reball, try running the benchmark again as you are monitoring the GPU temperature with GPU-Z (better yet, have GPU-Z -LOG- the temperatures.) Then you might be able to see at which point it crashes.
Better yet, here's another test, run a 3D game of your choice that loads the GPU, but not to 100%. For this, I prefer Valve's Source engine -based games and I impose an FPS limit through autoexec script. This allows me to keep GPU at a relatively steady load that I like... and relatively steady / lower temperature. If your card doesn't crash at this lower load, you most certainly have a dying GPU. RAM is less likely to get affected by this test, so if the test changes nothing, then one or more RAM chips might be conking out under load.
You can also use MSI Afterburner / Riva Tuner Statistics Server to limit FPS. I use this on non-Source -based games. In fact, I've started using this a lot more lately, due to being a bit lazy and not feeling like modding / putting an aftermarket cooler on all of my older cards. So in order to keep them cool(er) with their stock heatsink, I limit the FPS to keep GPU TDP lower... which in turn keeps the GPU temperatures lower.
pentiumspeed wrote on 2024-03-08, 00:44:See if you can isolate the issue with vram as issue by spot cooling with bagged one ice cube?
No offense, but that's a great way to RUIN any piece of electronic hardware that's not protected from moisture.
A bagged cube of ice will start to form condensation on the bag and then if any of this moisture makes it to the wrong places, you'll do a ton more damage.
The more "proper" way to spot-cooling is canned air turned upside down... though there are instances where I would advise against this too.
shamino wrote on 2024-03-08, 00:58:Try swapping to a different molex connector from another harness, unless you know the one you're using is good with other high powered cards.
Honestly, that's another myth that I keep seeing on various gaming forums, at least when it comes to these older GPUs. With new gen stuff pulling 200+ Watts and being a lot more sensitive voltage droop (due to current monitoring on the 12V rail - something that the GF6 series don't have... or even GPU power monitoring for that matter), I can understand.
That said, if the connector is dropping so much voltage because of a bad connection, you would see the connector melt / darken pretty quickly.