First post, by PlaneVuki
Hi!
My knowledge of assembly is weak-to-medium.
This started as simple image downscale attempt, but I will ask in general.
I am trying to copy data from one location to another, but neither source nor destination are consecutive. Like this:
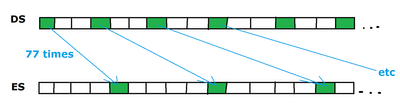
My code is this:
************************
mov cx,4D ;77 is 4D in hex
mov ax, destination_segment
mov es,ax
mov di,destination_offset
mov ax, source_segment
mov ds,ax
mov bx,source_offset
dostuff:
mov al,[bx]
mov [ es:di],al
add bx,3
add di,5
loop dostuff
************************
Is this the fastest method to do the copying (not considering loop unrolling)?
What faster way exist? What other improvements can be done?
If the destination is consecutive, I can do (inc di) instead of (add di,5), any other improvement available in this case?
Thanks in advance.


