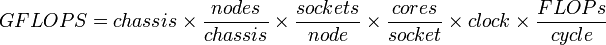No, he's roughly right.
The FLOPS/cycle at the end is the key and supposes that you know that number already (you do).
The rest is basically a fancy way of saying "Multiply the FLOPS of one core by the number of cores".
And you're almost never going to get an exact real-world number for it in a real system because of things like memory latency, etc. but that's not really important. I'm pretty sure what his prof is asking for is a theoretical assessment of what peak GFLOPS would be in an ideal world. You're never going to hit this number because of things like time spent on disk IO, message passing between nodes in your cluster, network latency, etc. The actual number is meaningless in a real-world sense. It just gives you a theoretical max - an estimation, so you can start talking about and comparing performance in some useful way.
Modern CPUs using SSE do ~4 floating point ops per cycle, so you'd basically just multiply the clock speed by four, then multiply by the number of cores in the cluster.
Ex. I just built a cluster with one chassis, four nodes per chassis, two sockets per node, six cores per socket @ 2.3GHz per core, so a total of 441.6 GFLOPS. It also runs 105.6 GFLOPS on the head node (different configuration, favours more and faster memory w/ quad-core CPUs) which can do computations as well, so a total of 547.2 GFLOPS.
Again, it's an estimation of the theoretical peak, not a real-world number.
If all else fails, use fire.