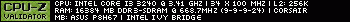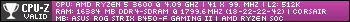First post, by leonardo

- Rank
- Oldbie
Nickname: Longbottom
- Case: Wings branded no-name
- Power supply: Fortron/FSP Group FSP-350 series (120mm fan)
- Motherboard: AOpen AX6BC Pro II Millennium Edition (this board is legendary)
- Processor: Intel Pentium III 1 GHz 'Coppermine' (7.5x133)
- Memory: 256 MB PC133 SD-RAM
- Video card(s): MSI MS-8838 AGP (NVIDIA GeForce 3 Ti 200, 64MB)
- Monitor(s): HP M700 17" CRT
- Sound card(s): Diamond MonsterSound MX300 (Aureal Vortex2) + Nec XR385 daughterboard
- Storage: Dual Seagate U Series X 20 GB HDDs
- Removable(s): Samsung SFD-321B/LEB 1.44 MB 3.5" + ASUS DVD-E612 & Plextor PX-W2410TA
- Connectivity: 3Com Fast Etherlink XL PCI 100 Mbit
- HIDs: IBM Model M (blue) and Logitech WheelMouse (ol' ballsy)
Brief description
Originally from a Finnish system integrator called Wings. I only kept the case because it's sturdy as hell and roomy enough to run an old system with just passive cooling. In fact the Slot1 CPU in this thing only has a huge heatsink on it. The PSU located right above it pulls warm air right out of the case. This makes the computer very quiet in operation. For maximum performance in late 90's and early 2000's titles, the system packs a GeForce 3 Ti200 which has excellent performance and driver support, and gives a nice clean image on the CRT. The AOpen AX6BC Pro II Millennium Edition could be blamed for starting the bling-bling trend on internal components with its stark color PCB, ridiculous naming, silver name plaque and "25 karat platinum" heatsink. 😆 For what it's worth, this is actually a very good, stable motherboard. Other peculiarities feature the DVD-drive which has a region-free "service" jumper. OS of choice: Windows 95 OSR2.
Photo gallery
See the new post for updated photos!
Build log / hardware & software updates
Replaced original motherboard (the AOpen AX6BC) and video card (a rare non-castrated/non-M64 PCI RivaTNT2 from ELSA) in a bid to increase performance for some of my later games such as NOLF, Deus Ex, and to be able to run games like WarCraft III or Max Payne that depended on DirectX 8 or later. I reluctantly upgraded to Windows 98SE and sure enough was reminded why I don't like Windows after 95. After a couple of reinstalls I got the hang of the system again and it now runs the more lean 95-version of Explorer to avoid IE and GUI lag.
Having to bring the CPU clock down to 750 MHz stings less than I thought it would, because for the games that I had 1 GHz was overkill anyway, but the graphics performance of the Radeon 9200 is heaps and bounds better than that of a PCI bus-based RivaTNT 2 (even the non-mutilated version).
3DMark2000 Benchmarks (before swap):
CPU @ 1 GHz (7.5x133), Creative 3DBlaster II (800x600x16): 1706 points
CPU @ 1 GHz (7.5x133), Elsa Synergy-II PCI (1024x768x16): 2320 points
3DMark2000 Benchmarks (after swap):
CPU @ 750 MHz (7.5x100) Sapphire Radeon 9200 VIVO AGP (1024x768x16): 5294 points
CPU @ 750 MHz (7.5x100) Sapphire Radeon 9200 VIVO AGP (1024x768x32: 5140 points
After (temporarily) going back to my trusty ELSA Synergy-II video card (and thus Windows 95), I decided to give the planned upgrade another go with a GeForce 3 Ti200 as the main video card this time (see thread about AGP overclocking and video cards). So far the GeForce 3 seems like a much better deal with performance at least on par with the Radeon 9200. The GeForce has drivers for Windows 95 and the card has also operated reliably with the CPU running at full 1 GHz speed (which requires a 133 MHz FSB, which ends up overclocking the AGP bus).
3DMark2000 Benchmarks (after swap):
CPU @ 1 GHz (7.5x133), MSI MS-8838 AGP (1024x768x16): 7215 points
CPU @ 1 GHz (7.5x133), MSI MS-8838 AGP (1024x768x32): 7025 points
[Install Win95 like you were born in 1985!] on systems like this or this.