Reply 120 of 154, by rasz_pl
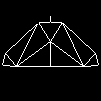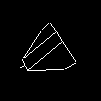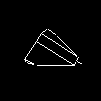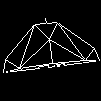
JohnBourno wrote on 2022-03-22, 12:58:What is interesting, is that without a FPU Duke Nukem 3d sometimes gets slowed down significantly. It drops from 20 frames per second to 7 fps in some scenes. Turns out that Duke3D uses floating point operations for rendering slopes. So without an FPU every time you have some slopes in your viewports the CPU has to do all the extra work and the game gets almost unplayable. Just by adding a IIS FPU the fps only drop to 15 instead of 7. So quite playable.
90MHz NexGen Nx586 drops down to 10fps on first screen with sloped roof for that very reason:
https://youtu.be/41O2bNG2qKA?t=234
Im sure today someone could come up with a faster integer/lookup table method of calculating those slopes.
https://github.com/raszpl/sigrok-disk FM/MFM/RLL decoder
https://github.com/raszpl/FIC-486-GAC-2-Cache-Module (AT&T Globalyst)
https://github.com/raszpl/386RC-16 ram board
https://github.com/raszpl/Zenith_ZBIOS Zenith Z-386 MFM-300 ZBIOS disassembly